1. NLTK & KoNLPy 설치
1.1 NLTK 설치
- pip install nltk
- pip install –upgrade nltk
- NLTK는 아나콘다를 설치했다면 기본으로 설치되어 있음
1.2 KoNLPy 설치
- pip install JPype1
- pip install konlpy
- pip install wordcloud
1.3 Punkt & Stopwords 설치
1
2
import nltk
nltk.download()
1
2
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
True
- 위의 코드를 입력하면 새로운 창이 하나더 뜸
- 거기서 All Packages탭을 선택 후 Punkt와 Stopwords를 download 함
2. 한국어 문서의 구성
2.1 구성 요소
문서 -> 문단 -> 문장 -> 어절 -> 형태소 -> 음절
- 문서 : 하나의 글 (기사, 소설 등)
- 문단 : 문서를 구성하는 요소, 보통 첫 시작은 ‘ ‘공백으로 이루어져서 나뉘어짐
- 문장 : . 으로 끝나는 요소, 모여서 문단을 구성함
- 어절 : 띄어쓰기로 나뉘어짐, 모여서 문장을 구성함
- 형태소 : 되, 었, 습니다, . 와 같이 언어의 최소 의미 단위
- 음절 : 습, 니, 다 와 같은 한 뭉치로 생각하는 발화의 단위. 음소보다 크고 낱말(단어)보다 작다. 음절은 자음과 모음 또는 단독 모음으로 구성됨
3. 실습
3.1 문장 (Sentences)
1
2
3
from konlpy.tag import Kkma
kkma = Kkma()
kkma.sentences('한국어 분석을 시작해봅시다. 잘 되나요?')
1
['한국어 분석을 시작해 봅시다.', '잘 되나요?']
- 한국어 분석을 위한 konlpy의 Kkma 를 사용함
- 일단 sentences 메서드를 사용하여 문장을 분석함
3.2 명사 (Nouns)
1
kkma.nouns('한국어 분석을 시작해 봅시다.')
1
['한국어', '분석']
- nouns 메서드를 사용사여 명사를 추출함
3.3 품사 (Pos)
1
kkma.pos('한국어 분석을 시작해 봅시다.')
1
2
3
4
5
6
7
8
[('한국어', 'NNG'),
('분석', 'NNG'),
('을', 'JKO'),
('시작하', 'VV'),
('어', 'ECS'),
('보', 'VV'),
('ㅂ시다', 'EFA'),
('.', 'SF')]
- 품사를 분석하는 pos 메서드를 사용
3.4 형태소 (Morpheme)
1
kkma.morphs('한국어 분석을 시작해 봅시다.')
1
['한국어', '분석', '을', '시작하', '어', '보', 'ㅂ시다', '.']
- morphs를 사용하여 형태소 단위로 분석함
4. Word Cloud
4.1 Word Cloud 실행
1
2
3
4
5
6
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from PIL import Image
- Word Cloud를 구성하기 위한 패키지를 import 함
4.2 Alice
1
2
3
4
5
text = open('data/alice.txt').read()
stopwords = set(STOPWORDS)
stopwords.add('said')
list(stopwords)[:3]
1
["they've", 'i', 'ours']
- https://github.com/hmkim312/datas/tree/main/alice
- 실습에 사용한 데이터는 위 링크에 있음
- alice : 이상한 나라의 엘리스의 영어 단어본
- stopwords : 분석에 사용하지 않을 단어들의 모음, 보통 의미가 중복되는것이 들어가있음, said라는 단어를 추가 시킴
4.3 Mask 해보기
1
2
3
4
5
alice_mask = np.array(Image.open('data/alice_mask.png'))
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap = plt.cm.gray, interpolation='bilinear')
plt.axis('off')
plt.show()

- 이상한 나라의 엘리스이니, 엘리스 모양의 그림을 가져와서 WordCloud를 해보기로함
- 위의 링크에 사진파일도 있음
4.4 단어 빈도 확인
1
2
3
wc = WordCloud(background_color='white', max_words=2000, mask=alice_mask, stopwords= stopwords)
wc = wc.generate(text)
wc.words_
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{'Alice': 1.0,
'little': 0.29508196721311475,
'one': 0.27595628415300544,
'know': 0.2459016393442623,
'went': 0.226775956284153,
'thing': 0.2185792349726776,
'time': 0.2103825136612022,
'Queen': 0.20765027322404372,
'see': 0.1830601092896175,
'King': 0.17486338797814208,
'well': 0.1721311475409836,
'now': 0.16393442622950818,
'head': 0.16393442622950818,
'began': 0.15846994535519127,
'way': 0.1557377049180328,
'Hatter': 0.1557377049180328,
'Mock Turtle': 0.15300546448087432,
...}
- 총 2000개 단어의 빈도를 확인해봄
- Alice가 가장 많음, stopwords안의 단어들은 빈도수 조사가 안됨
4.5 WordCloud 시각화
1
2
3
4
plt.figure(figsize=(12,12))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
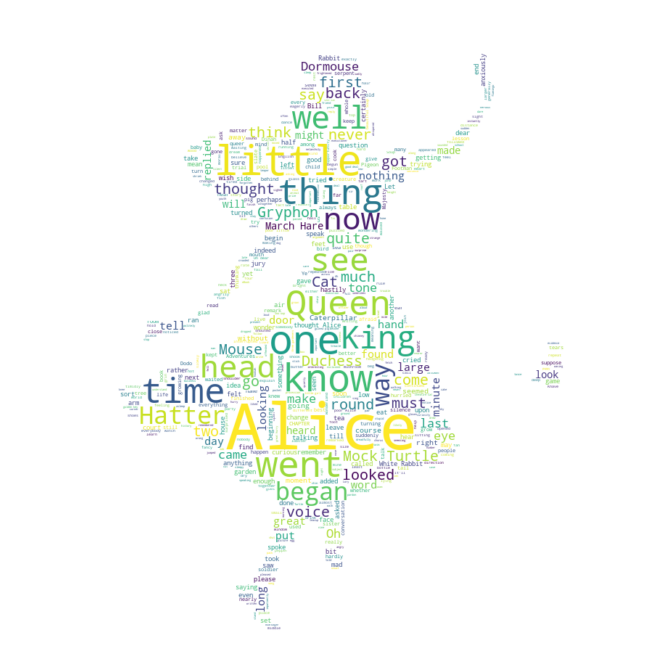
- 단어의 빈도수에 따라 엘리스모양의 그림에 생겨짐
5. 설치 시 JAVA 오류일때
5.1 JAVA SDK 설치
- https://www.oracle.com/java/technologies/javase-downloads.html
- 위의 링크에서 JDK Download 후 본인의 운영체제에 맞는걸로 설치
5.2 환경변수 추가
- Windows : 시스템 변수에 추가해야함 변수이름은 JAVA_HOME으로, 변수값은 Jdk가 설치된 경로로 추가
- Mac :
export JAVA_HOME $(/Library/Java/JavaVirtualMachines/)을 터미널에 입력